On this page
Subscribe to receive the latest blog posts to your inbox every week.
By subscribing you agree to with our Privacy Policy.
When you manage 50+ corporate sites across regions and time zones, the hard part is preventing small, local issues from turning into portfolio-wide patterns. You’re thinking about what happens when the same “comfort complaint” shows up in five buildings across three regions, handled by three different vendors, and leadership wants clarity fast:
“Is this an isolated incident… or the start of something bigger?”
Your day stops being maintenance and becomes risk management. How do you keep performance consistent across all of it?
You’re accountable for uptime, SLA compliance, backlog health, repeat issues, documentation, and cost control, and you sit between worlds:
Most days, the hardest part isn’t making decisions. It’s getting to a place where you can make one without second-guessing the data. Maintenance data usually lives in too many places: CMMS records, BAS exports, vendor notes in email, outdated spreadsheets, attachments scattered across drives, and “status updates” that don’t reconcile. Everyone is working from different definitions and records, which slows everything down.
So here’s your day, split into two timelines:
The morning starts with updates focused on different directions:
You try to answer basic questions that should take minutes:
What’s truly overdue?
What’s at risk?
What’s repeating?
But you’re short on alignment. The same asset appears under different names across systems. One system calls it “FCU-3,” another calls it “Unit 3,” and the vendor invoice references a third label.
So before you’ve made a single decision, you’re reconciling records.
If the first hour is spent just getting “one version of truth,” the system is the problem.
Leadership wants quick clarity:
What’s driving overdue work?
Which sites are trending worse?
Are repeat issues tied to the same vendors, the same systems, or both?
You pull CMMS data, but it doesn’t reflect what changed on-site, what the vendor actually did, or whether the “fix” held. So you paste together a narrative from a report, a few emails, and a spreadsheet.
It looks presentable, but not the kind of visibility you want when decisions affect spend, workplace continuity, and risk.
A site requests: “Replace actuator on FCU. Comfort complaints.”
You ask for details.
You try to validate the basics:
Is this the same FCU that was recently serviced?
Is this a repeat issue?
Now you’re digging for evidence to answer what should be one question: What’s actually happening with this asset?
You know the portfolio needs consistent PM and inspections. But in most environments, schedules live in spreadsheets, tasks are defined differently across regions, documentation quality varies wildly, and you can’t see workload collisions across the portfolio.
The moment corrective work spikes, PM is what gets pushed.
Not because anyone is careless, but because the system can’t protect consistency.
So you end up with:
Backlogs,
Repeat failures, and
Emergency spending
…from losing control of standardization.
A compliance request lands. You’re asked for: inspection completion, servicing records, proof of servicing for a set of critical assets, attachments, and closeout evidence.
You start searching across CMMS attachments (if they were uploaded), vendor PDFs (if they were emailed), internal folders (if named correctly), and FM provider portals (if you have access).
You eventually assemble what you can, but you still can’t confidently answer whether this is complete, current, or defensible.
Work moved forward through coordination, but you still don’t have a clear view of which overdue items are truly high-impact, which recurring issues indicate deeper asset problems, which vendors are missing SLAs and why, and which spending is avoidable if schedules were consistent.
The day ends with movement but not enough confidence.
What’s most at risk across the portfolio today?
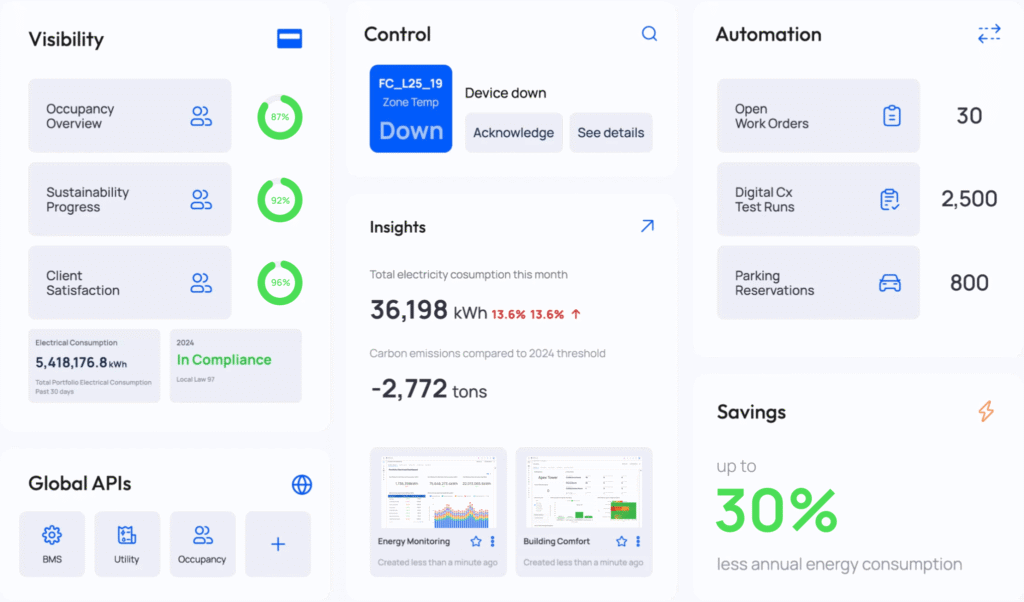
Instead of starting with email, you open AssetOps and start with an operational view of the portfolio:
It doesn’t mean problems disappear, but now, when an escalation arrives, you already know where to focus.
This is the difference between reacting and operating.
A vendor sends a repair request. You open the asset in AssetOps and see the story in one place:
a unified asset record across sources (OT + physical),
recent PM and corrective history tied to that asset,
notes and photos from the field,
attachments that actually stay with the work,
traceability for what came from where (so you can trust it).
Instead of duplicates and mismatched IDs, AssetOps reconciles multi-source identity and keeps the work history connected.
You can quickly validate the recommendation by seeing what’s been tried before, whether the issue recurs, and whether it is a one-off or a pattern.
You stop debating the asset name and start solving the problem.
This is where most portfolios quietly lose.
Because the failure mode isn’t “no PM.”
It’s PM that exists, but isn’t consistent.
Asset Ops helps you standardize how work is defined and executed:
So PM starts running like it should: scheduled, visible, trackable, and defensible.
This is how you reduce repeat issues without playing whack‑a‑mole.
A site escalation comes in.
You create (or open) the corrective work order in Asset Ops and link it to:
the asset and location,
relevant PM history,
prior corrective work, and
follow-ups if verification is required.
Even if execution routes through an external system, your history stays whole. The record doesn’t vanish into a vendor portal.
This is how you prevent the classic failure loop:
Issue → Vendor “fix” → No verification → Same issue again → Emergency spend
In AssetOps, the full cycle stays connected:
Issue → Action → Verification → History
When a provider says “in progress,” you can validate it with real status updates and timelines.
You can see:
SLA performance by vendor,
overdue trends by category and site,
where work is getting stuck,
reopen patterns,
documentation/closeout consistency.
Vendor conversations change. Instead of debating status, you’re aligned on the same data, and you can remove blockers faster.
This is where teams feel the shift of less escalation, with much fewer surprises, and cleaner closeouts.
Leadership asks for a portfolio check. You generate a clear snapshot from Asset Ops that you can defend:
You walk into the meeting with: what’s urgent, what’s recurring, and what’s preventable.
And because the underlying records are connected, your narrative holds.
Enterprise portfolios will always be complex. But you don’t end the day wondering which system is right, whether the “fix” held, or whether you’re seeing the whole picture.
AssetOps doesn’t make buildings simple, it makes operations coherent.
You finish with a clear backlog view, standardized PM in motion, corrective work tied to asset history, and portfolio reporting you can act on.
The win is reducing the unknowns created by disconnected systems.
If you want a quick self-check, ask your team:
If those feel hard, you’re not alone.
But you don’t have to keep operating that way.
Asset Ops in KODE OS is built for the reality of enterprise portfolios: multiple sites, multiple providers, mixed ownership models, and workflows spread across various tools.
It helps you run maintenance like a system:
If this day feels familiar and you want to see what it looks like when asset records, schedules, and work orders live in one place, request an Asset Ops walkthrough.
We’ll show you what maintenance management looks like when the portfolio runs on one system.
Ard Stavileci
Product Director, KODE Labs
News, insights and resources from the world of smart building management.
By clicking "Sign Up" you're confirming that you agree with our Terms and Conditions.
What does the Functional Testing Tool do? For building integrators, functional testing becomes difficult at scale. Testing one fan coil…
Read more

Originally published on Facility Executive The next phase of facility management relies on unified data streams to optimize building performance,…
Read more

June strengthens the KODE OS integration ecosystem with a new governed Public API for AssetOps and expanded connectivity for physical…
Read more